牛顿法以及用牛顿法求极值
牛顿法
牛顿法经常作为一个和梯度下降做对比的求解机器学习收敛结果的方法。需要明确的是首先牛顿法本身是作为求解函数零点问题的一种方法。具体做法是:当想要求解 $ f(\theta)=0 $ 时,如果$f$可导,那么可以通过迭代公式:
$ \theta :=\theta-\frac{f(\theta)}{f^{\prime}(\theta)} $
来迭代求得零点。
需要注意的是,牛顿法根据选取的初始值的不同,有可能会不收敛!通常选取在零点附近作为初始值。
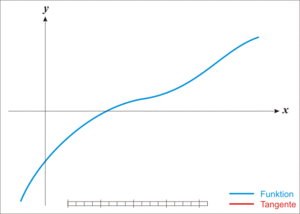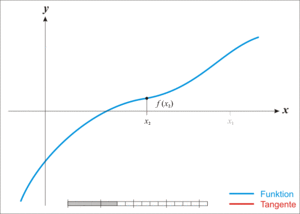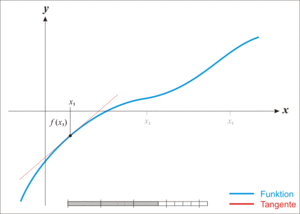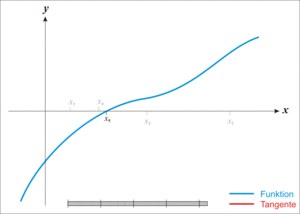 |
| 牛顿法求函数零点 |
我们把$ f(x)=0 $在$x_0$处展开且展开到一阶,得到$f(x)=f\left(x_{0}\right)+f^{\prime}\left(x_{0}\right)\left(x-x_{0}\right)$ 所以目标就变成了要让:$f\left(x_{0}\right)+f^{\prime}\left(x_{0}\right)\left(x-x_{0}\right)=0$ 所以就变成了:$x=x_{1}=x_{0}-\frac{f\left(x_{0}\right)}{f^{\prime}\left(x_{0}\right)}$
因为$f(x)=f\left(x_{0}\right)+f^{\prime}\left(x_{0}\right)\left(x-x_{0}\right)$ 并非处处相等,而是只在$x_0$附近可以这么认为,这里求得的$x_1$并不能让$f(x) = 0$,只能说$f(x_1)$的值比$f(x_0)$更接近于0,所以这就可以用迭代来逼近了!
这里来插入一下如果自变量不是一个单变量的泰勒展开式,假设函数$f(x,y)$ 那么它在$(x0,y0)$处的一阶泰勒展开计作$L(x,y)$写作:
$L(x,y) = f(x_0,y_0) + f_x(x_0,y_0)*(x-x_0) + f_y(x_0,y_0)*(y-y_0)$
牛顿法求极值
在机器学习中,问题就不是求零点,而是希望求loss function的最小值,于是可以写作求$\ell^{\prime}(\theta)=0$ 同理,这种情况下的迭代过程就是:
牛顿法求极值之所以work,是因为利用了泰勒二阶展开。
$ \theta :=\theta-\frac{\ell^{\prime}(\theta)}{\ell^{\prime \prime}(\theta)} $
回忆一下梯度下降的公式:
$\theta_{j} :=\theta_{j}-\alpha \frac{\partial}{\partial \theta_{j}} J(\theta)$
这里就可以看出和梯度下降的对比了:这个与梯度下降不同,梯度下降的目的是直接求解目标函数极小值,而牛顿法则变相地通过求解目标函数一阶导为零的参数值,进而求得目标函数最小值
 |
| 红色是牛顿法的收敛路径 绿色是梯度下降的收敛路径 |
牛顿法求极值之所以work,是因为利用了泰勒二阶展开。
函数$f(x)$在$x_k$处的二阶泰勒展开计作$\phi(x)$,写作:
$\phi(x)=f\left(x_{k}\right)+f^{\prime}\left(x_{k}\right)\left(x-x_{k}\right)+\frac{1}{2} f^{\prime\prime}\left(x_{k}\right)\left(x-x_{k}\right)^{2}$
既然我们想要求$f(x)$的极值,所以令其导数为0,即:$f^{\prime}(x)=0$ ,用二阶泰勒展开式替代的话就是:$\phi^{\prime}(x)=0$ 对上式求导的话,就是:
$\phi^{\prime}(x)=f^{\prime}(x_k)+f^{\prime\prime}\left(x_{k}\right)\left(x-x_{k}\right)=0$
所以就变成了:
$x=x_{k}-\frac{f^{\prime}\left(x_{k}\right)}{f^{\prime\prime}\left(x_{k}\right)}$
这里再插入一下,如果自变量是多元的情况下的二阶泰勒展开公式:
$Q(x, y)=f\left(x_{0}, y_0\right)+f_{x}\left(x_{0}, y_0\right)\left(x-x_{0}\right)+f_{y}\left(x_{0}, y_{0}\right)\left(y-y_{0}\right) $
$ + f_{x x}\left(x_{0}, y_{0}\right)\left(x-x_{0}\right)^{2}+f_{x y}\left(x_{0}, y_{0}\right)\left(x-x_{0}\right)\left(y-y_{0}\right)+f_{yy}\left(x_{0}, y_{0}\right)\left(y-y_{0}\right)^{2}$
用这样的符号写起来就很啰嗦,通常人们就会vectorize这样的写法:
$Q(X)=f\left(X_{0}\right)+\nabla f\left(X_{0}\right)\left(X-X_{0}\right)+\frac{1}{2}\left(X-X_{0}\right)^{T} H_{f}\left(X_{0}\right)\left(X-X_{0}\right)$
其中:
$\nabla f=\left[ \begin{array}{c}{\frac{\partial f}{\partial x_{1}}} \\ {\frac{\partial f}{\partial x_{2}}} \\…\\ {\frac{\partial f}{\partial x_{N}}}\end{array}\right]$
$H_f = \nabla^2{f}=\left[ \begin{array}{cccc}{\frac{\partial^{2} f}{\partial x_{1}^{2}}} & {\frac{\partial^{2} f}{\partial x_{1} \partial x_{2}}} & {\cdots} & {\frac{\partial^{2} f}{\partial x_{1} \partial x_{N}}} \\ {\frac{\partial^{2} f}{\partial x_{2} \partial x_{1}}} & {\frac{\partial^{2} f}{\partial x_{2}^{2}}} & {\dots} & {\frac{\partial^{2} f}{\partial x_{2} \partial x_{N}}} \\ {\vdots} & {\vdots} & {\ddots} & {\vdots} \\ {\frac{\partial^{2} f}{\partial x_{N} \partial x_{1}}} & {\frac{\partial^{2} f}{\partial x_{N} \partial x_{2}}} & {\cdots} & {\frac{\partial^{2} f}{\partial x_{N}^{2}}}\end{array}\right]$
这里$H_f(X_0)$代表的是$f$ 在$X=X_0$取值的Hessian Matrix
于是如果vectorize牛顿法求极值,就让$Q^{\prime}(X) = 0$, 即
$Q^{\prime}(X) = \nabla f\left(X_{k}\right)+ H^{-1}_{f}\left(X_{k}\right)\left(X-X_{k}\right) = 0$
整理可得迭代式:
$X_{k+1}=X_{k}-H^{-1}_{k} \nabla f\left(X_{k}\right)$
ref:



Comments
Post a Comment